
Desde el surgimiento de la World Wide Web (WWW) en los años 90 presentada como un proyecto en la Organización Europea para Investigación Nuclear (CERN) en Ginebra (Suiza) por TimBerners-Leey Robert Cailliau, la web se ha convertido en un instrumento de uso cotidiano en nuestra sociedad y para muchos una necesidad de vida . El constante desarrollo y avance de las tecnologías de la comunicación y la información ha demandado numerosos cambios significativos en la web. Muchos artículos nombran a las etapas o cambios de la web por números como ejemplo la web 2.0, web 3.0 o web semántica.

A finales de los años 90 la W3C empieza a plantearse la idea de web semántica, pero fue en 2001 cuando se presenta un artículo en la revista Scientific American en el que se describen las nuevas características de la web semántica. La propuesta de Tim Berners- Lee en 2001 pretende transformar la web actual la cual se basa en el lenguaje natural, tiene una falta de estructuración de contenidos y una carencia de descripciones normalizadas para los recursos digitales, lo que se ve reflejado en la ambigüedad de los resultados que recuperan los motores de búsqueda.
Recuperación de Información
Los nuevos Sistemas de Recuperación de Información reflejan la poca relevancia de los documentos recuperados para cubrir la necesidad de información del usuario. Esta situación conlleva a la idea de la web semántica, cuyo objetivo es identificar la información de forma unívoca y establecer relaciones entre los objetos digitales con miras a facilitar una recuperación eficaz de la información.

La Web Semántica como antes se mencionaba pretende clasificar, dotar de estructura y anotar los recursos con semántica para ser procesadas por máquinas. Esta estructura se puede considerar como un gran grafo como se muestra en la siguiente figura.

Principales Características de la Web Semántica
Entre las características más importantes de la Web Semántica podemos encontrar:
• La Web considerada como una gran base de datos.
• Metadatos y lógica formal.
• Ontologías.
• Agente de usuario y sistemas informáticos capaces de efectuar inferencias o razonamientos.
El gran reto de la Web Semántica consiste en desarrollar una serie de tecnologías que permitieran a los ordenadores, a través del uso de agentes de usuarios parecidos a los navegadores actuales, no solo interpretar y comprender el contenido de las páginas web, sino además efectuar razonamientos sobre el mismo, de modo que las computadoras realicen tareas complejas como la IR con un rendimiento similar al de las personas.
La Web Semántica plantea ventajas significativas con respecto a la web 2.0 entre las cuales se encuentran:
• Incorporación de contenido semántico a las páginas que se utilizan en la Internet. Esto permite una mejor organización de la información, asegurando búsquedas más precisas por significado y no por contenido textual.
• Permite a las computadoras la gestión del conocimiento.
Es importante puntualizar que todavía la web no ha logrado adaptarse completamente a dichos cambios, este sería un proceso no tan ágil a causa del gran volumen y variedad de la información y de los sistemas informáticos, sin contar la diversidad en los idiomas. Además, es necesario unificar los estándares semánticos y proveer relaciones de equivalencia entre conceptos.
En muchos artículos se ha planteado una forma de solucionar este problema, el cual consiste en compartir ontologías para las áreas comunes en que puede tener lugar una interacción o intercambio de información entre las partes, también se deben establecer formas de compatibilidad con las ontologías locales, mediante extensión y especialización de las ontologías genéricas, o por mapeo y exportación entre ontologías.
En la siguiente imagen se muestra una comparación entre las distintas etapas de la web y su relación con el ciberperiodismo en forma de tabla recalcando puntos comparativos como áreas, tecnologías y se reflejan además ejemplos de sistemas desarrollados.

El intercambio de conocimientos en la web semántica
Generalizando la idea esencial es que los datos puedan ser utilizados y “comprendidos” por los ordenadores sin necesidad de supervisión humana, de forma que los agentes web puedan ser diseñados
para tratar la información situada en las páginas web de manera semiautomática. Se trata de convertir la información en conocimiento, referenciando datos dentro de las páginas web a metadatos con un esquema común consensuado sobre algún dominio.
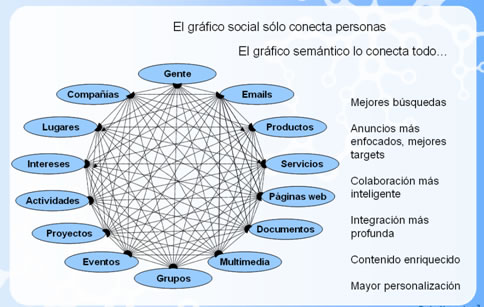
Los metadatos no sólo especificarán el esquema de datos que debe aparecer en cada instancia, sino que además podrán tener información adicional de cómo hacer deducciones con ellos, es decir, axiomas que podrán aplicarse en los diferentes dominios que trate el conocimiento almacenado. Con ello, se mejorará la búsqueda de información y se potenciará el desarrollo de aplicaciones de comercio electrónico, ya que las anotaciones de información seguirán un esquema común, y los buscadores web compartirán con las anotaciones web los mismos esquemas.
Empresas que traten con clientes y proveedores, podrán intercambiar sus datos de productos siguiendo estos esquemas comunes consensuados. Los agentes web no sólo encontrarán la información de forma precisa, si no que podrán realizar inferencias automáticamente buscando información relacionada con la que se encuentra situada en las páginas, y con los requerimientos de la consulta indicada por el usuario.